第一章:研究背景与动机
1.1 多模态学习与域适应
1.1.1 多模态学习的价值与挑战
多模态学习(Multimodal Learning)通过整合来自多个感知通道的异构互补信号(如声学、视觉和语言信息)来完成机器学习任务,包括分类、聚类和检索等。得益于硬件和模型设计的最新进展,多模态学习已被广泛应用于动作识别、情感计算和医学分析等领域。
与单模态方法相比,多模态学习能够取得显著的性能提升。然而,其 notorious 的缺点是:收集和标注多模态数据既昂贵又耗时。因此,标注数据的稀缺性成为多模态学习实际应用中的主要挑战。
1.1.2 无监督域适应的定义
无监督域适应(Unsupervised Domain Adaptation, UDA)旨在将知识从标注丰富的源域(Source Domain)迁移到无标注但相关的目标域(Target Domain),从而在不增加标注成本的前提下提升模型在新环境中的表现。
主流方法通常通过以下两种途径对齐源域和目标域:
- 直接最小化特征分布差异:如基于矩匹配的方法(MMD、CORAL)
- 对抗学习:训练域判别器与特征提取器进行对抗博弈(DANN、CDAN)
这些方法在图像分类、语义分割、目标检测和问答系统等多种任务上展示了令人印象深刻的结果。
1.1.3 多模态域适应的特殊性
现有的域适应文献主要集中在单模态场景(特别是计算机视觉和自然语言处理领域)。相比之下,多模态域适应的研究相对较少,但由于多模态学习的普及,该领域正受到越来越多的关注。
从模态多样性的角度,多模态域适应可分为两类:
(1)同质多模态适应(Homogeneous Multimodal Adaptation)
关注多个模态共享相似底层结构或环境的场景。例如:
- 多模态视觉域适应任务中的 2D 图像和 3D 点云
- 光流和 RGB 图像
- CT 和 MRI 图像
在这种情况下,不同模态的源域和目标域之间的差距相对较小,可以对各模态的域进行统一对齐。
(2)异质多模态适应(Heterogeneous Multimodal Adaptation)
处理不同模态具有不同形式并处于独立空间的场景。一个典型例子是多模态情感识别任务,如图 1 所示:
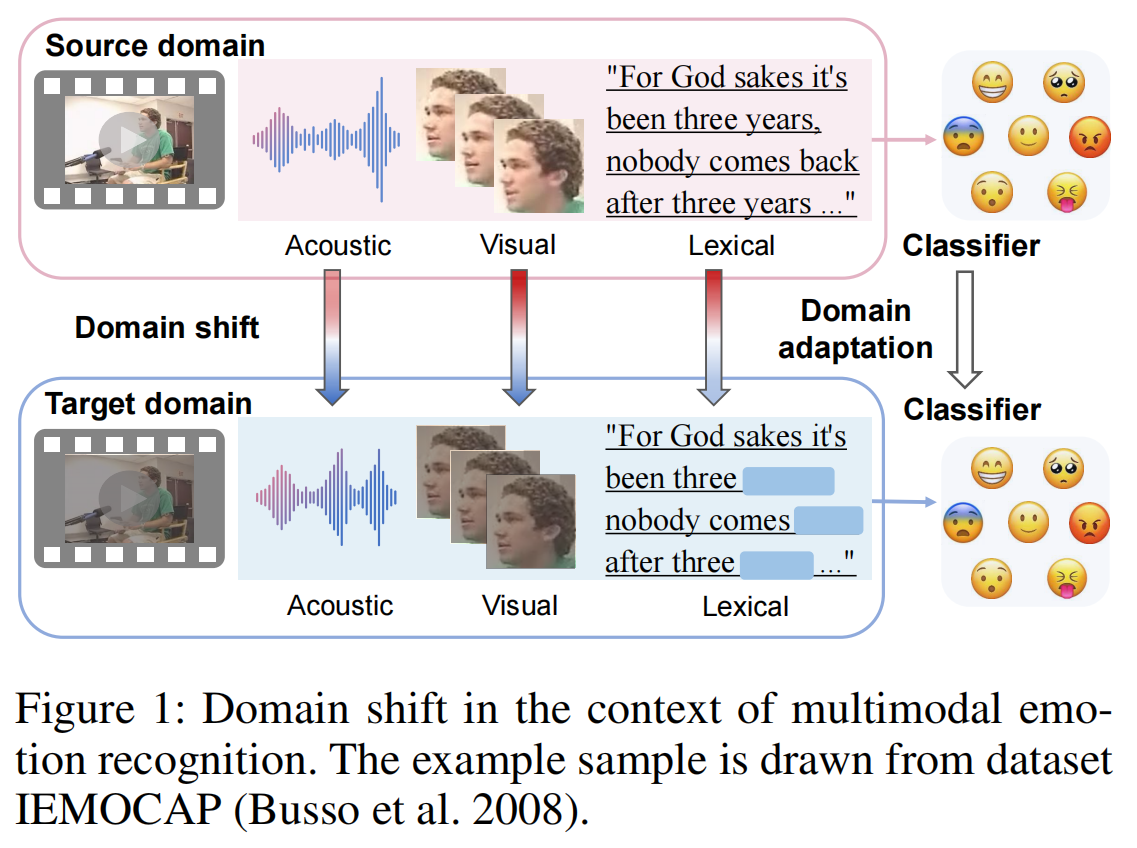
图 1:多模态情感识别中的域偏移。示例样本来自 IEMOCAP 数据集。
在该任务中,声学、视觉和词汇模态被同时用于检测情绪。每个模态面临不同的域偏移因素:
- 声学模态:背景噪声
- 视觉模态:光照变化
- 词汇模态:对话场景变化
这自然导致不同模态从源域到目标域的分布偏移程度各不相同。
1.2 同质与异质多模态域适应
1.2.1 同质适应的特点
在同质多模态适应中,不同模态的数据通常来自同一类型的传感器或具有相似的数据结构。例如:
- RGB 图像和光流都基于视觉信息
- CT 和 MRI 都是医学影像
由于模态间的相似性,源域和目标域的偏移在各模态间大致相当,因此可以采用统一的对齐策略。
1.2.2 异质适应的挑战
异质多模态适应更具挑战性,原因如下:
- 模态间差异大:声学信号(波形或频谱)、视觉图像(像素矩阵)和文本(词向量序列)具有完全不同的数据结构
- 域偏移程度不同:各模态面临不同的环境因素,导致从源域到目标域的分布偏移程度差异显著
- 模态间竞争:直接将单模态域适应技术应用于异质多模态设置可能导致不同模态的对齐不平衡
1.2.3 模态不平衡现象
模态不平衡(Modality Imbalance)是指在训练过程中,某些模态主导训练而其他模态训练不足的现象。这与多模态学习中观察到的"贪婪学习"(Greedy Learning)问题密切相关:
- 不同模态以不同的速率泛化和过拟合
- 某些强模态可能主导训练并抑制其他弱模态
- 这导致模型无法充分利用所有模态的互补信息
现有的多模态学习方法通过以下方式缓解这一问题:
- 根据过拟合估计调节学习率
- 基于梯度进行动态调整
- 利用各模态的损失优势进行平衡
- 知识蒸馏和自蒸馏技术
1.3 模态不平衡问题
1.3.1 问题的具体表现
在多模态域适应中,模态不平衡表现为:
- 某些模态主导域对齐:例如,视觉模态由于特征维度高、表达能力强,其域对齐损失可能主导整体优化,导致声学模态的对齐被忽视
- 弱模态的表示学习不足:训练结束后,弱模态的表示质量较差,影响融合后的最终性能
- 融合性能不升反降:在某些情况下,增加模态数量反而导致性能下降(如论文中观察到的 DALN 和 DANN 现象)
1.3.2 现有方法的局限
现有的域适应方法在处理多模态场景时存在以下局限:
- 统一对齐策略的不足:将各模态的域对齐损失简单加总或加权平均,无法适应各模态动态变化的偏移程度
- 固定权重的僵化性:预设的固定权重无法适应训练过程中对齐损失的动态变化
- 缺乏理论指导:权重选择往往依赖经验或大量调参,缺乏系统的优化框架
1.4 Boomda 的核心思想
1.4.1 方法概述
Boomda(Balanced multi-objective optimization for multimodal domain adaptation)提出了一种平衡的多目标优化框架,核心思想包括:
- 基于信息瓶颈的独立表示学习:为每个模态独立学习最优表示,促进模态独立性
- 相关对齐(Correlation Alignment):在各模态的表示空间中对齐源域和目标域
- 多目标优化平衡:将各模态的对齐目标建模为多目标优化问题,通过 MGDA 算法求解 Pareto 最优解
- 高效闭式解:利用模型结构的特殊性质,推导出近似问题的闭式解,实现高效训练
1.4.2 核心优势
| 特性 | 传统方法 | Boomda |
|---|---|---|
| 表示学习 | 联合表示,模态易互相干扰 | 信息瓶颈,各模态独立优化 |
| 域对齐 | 统一加权求和 | 多目标优化,Pareto最优 |
| 权重选择 | 预设固定权重 | 动态自适应求解 |
| 计算效率 | 需迭代优化权重 | 闭式解,计算开销小 |
| 模态平衡 | 缺乏系统保证 | 理论保证的模态平衡 |
本节小结
- 多模态域适应分为同质和异质两类,异质适应更具挑战性
- 异质多模态适应中,不同模态面临不同程度的域偏移,导致模态不平衡问题
- 现有方法多采用统一对齐策略或固定权重,无法有效平衡各模态
- Boomda 通过信息瓶颈、相关对齐和多目标优化三大组件,系统性地解决了模态不平衡问题
思考题
- 为什么异质多模态域适应中,各模态的域偏移程度会不同?请结合具体应用场景说明。
- 模态不平衡问题在单模态域适应中是否存在?为什么在多模态场景中更加突出?
- 将各模态的域对齐损失简单求和,在什么情况下会导致性能下降?