第二章:核心方法详解
2.1 问题定义与符号系统
2.1.1 符号定义
我们首先建立统一的符号表示:
- 样本数:$N$,模态数:$M$
- 引入一个辅助模态(包含所有模态的融合表示),总模态数为 $M + 1$
- $[I]$ 表示集合 ${1, 2, \ldots, I}$
- 训练样本:$\left({x_{n,m}}_{m \in \lbrack M \rbrack}, {y_{n,m}}_{m \in \lbrack M+1 \rbrack}\right)$
- $n \in [N]$:样本索引
- $x_{n,m} \in \mathbb{R}^{d_m}$:模态 $m$ 的 $d_m$ 维特征向量
- $y_{n,m}$:模态 $m$ 的标签(标量或 one-hot 向量)
- 当所有模态共享相同标签时:$y_{n,1} = y_{n,2} = \cdots = y_{n,M+1}$
- 类别数:$C$
-
融合模态特征:$x_{n,M+1} := [x_{n,1}; x_{n,2}; \cdots; x_{n,M}]$
-
随机变量:
- $X_m$ 和 $Y_m$:模态 $m$ 的特征和标签随机变量
- $Z_m \in \mathbb{R}^d$:模态 $m$ 的表示(假设所有模态表示维度均为 $d$)
-
$z_{n,m}$:$Z_m$ 的具体实例
-
域区分:上标 $s$ 和 $t$ 分别表示源域和目标域
- $X_m^s$ 和 $X_m^t$:模态 $m$ 在源域和目标域的特征
2.1.2 问题目标
给定源域的标注数据和目标域的无标注数据,学习一个多模态模型,使得:
1. 各模态独立学习到最优表示
2. 源域和目标域的表示分布在各模态上得到良好对齐
3. 各模态的对齐过程得到平衡,避免某些模态主导优化
2.2 模型框架总览
2.2.1 整体架构
Boomda 的模型框架如图 2 所示(以两模态为例,$M=2$):
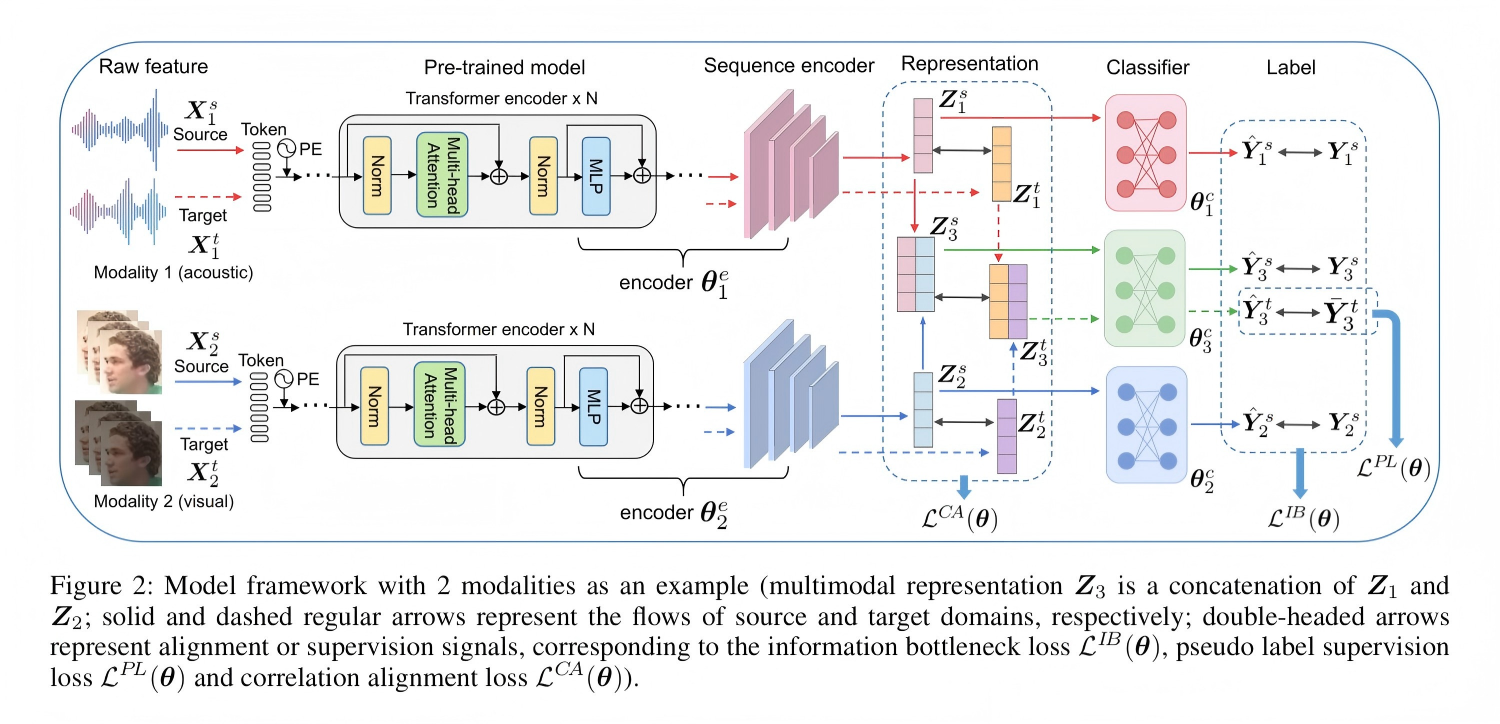
图 2:以两模态(视觉和声学)为例的模型框架。$Z_3$ 是 $Z_1$ 和 $Z_2$ 的拼接;实线和虚线常规箭头分别表示源域和目标域的流向;双箭头表示对齐或监督信号,对应信息瓶颈损失 $L_{IB}(\theta)$、伪标签监督损失 $L_{PL}(\theta)$ 和相关对齐损失 $L_{CA}(\theta)$。
2.2.2 组件说明
(1)预训练骨干网络
对于每个模态 $m \in [M]$,原始特征 $X_m$ 首先经过 tokenization,然后输入预训练的基于 Transformer 的模型。预训练模型的顶层将进行微调,其余层冻结。
(2)序列编码器
在预训练模型之后,序列编码器进一步将序列特征编码为向量表示 $Z_m$。形式化地,对于每个模态 $m$,预训练模型和序列编码器共同构成一个确定性编码器函数:
$$f_m^e(\cdot; \theta_m^e): \mathbb{R}^{d_m} \rightarrow \mathbb{R}^d$$
其中 $\theta_m^e$ 为可训练参数。于是有:
$$Z_m = f_m^e(X_m; \theta_m^e)$$
(3)多模态表示
多模态表示定义为所有模态表示的拼接:
$$Z_{M+1} := [Z_1, Z_2, \cdots, Z_M]$$
(4)分类器
每个模态 $m \in [M+1]$ 配有一个分类器 $f_m^c(\cdot, \theta_m^c)$,用于标签预测:
$$\hat{Y}_m = f_m^c(Z_m, \theta_m^c)$$
多模态预测 $\hat{Y}_{M+1}$ 作为最终的预测标签。
2.3 信息瓶颈表示学习
2.3.1 信息瓶颈理论
信息瓶颈(Information Bottleneck, IB)理论旨在学习一种表示,使其保留与标签相关的最少但足够的信息。形式上,最优表示通过最小化以下 IB 损失获得:
$$L_{IB}(\theta) := \sum_{m \in [M+1]} \beta I(X_m^s, Z_m^s) - I(Z_m^s, Y_m^s)$$
其中 $I(\cdot, \cdot)$ 表示互信息,$\beta$ 是预定义的系数。
直观理解:
- $I(X_m^s, Z_m^s)$ 表示表示 $Z_m^s$ 保留的原始特征信息量(越小越好,实现压缩)
- $I(Z_m^s, Y_m^s)$ 表示表示 $Z_m^s$ 与标签的互信息(越大越好,保留判别信息)
- 平衡两者即可得到"瓶颈"表示
2.3.2 互信息的计算
(1)$I(X_m^s, Z_m^s)$ 的计算
由于 $Z_m = f_m^e(X_m; \theta_m^e)$ 是确定性函数,条件熵 $H(Z_m^s | X_m^s) = 0$。因此:
$$I(X_m^s, Z_m^s) = H(Z_m^s) - H(Z_m^s | X_m^s) = H(Z_m^s) = \mathbb{E}_{Z_m^s}[-\log p(Z_m^s)]$$
假设 $p(Z_m^s)$ 服从高斯分布 $\mathcal{N}(\mu_m^s, \Sigma_m^s)$,则熵为:
$$H(Z_m^s) = \frac{1}{2} \log |\Sigma_m^s| + \frac{d}{2}(1 + \log(2\pi))$$
(2)$I(Z_m^s, Y_m^s)$ 的计算
$$I(Z_m^s, Y_m^s) = H(Y_m^s) - H(Y_m^s | Z_m^s) = H_{Y,m}^s + \frac{1}{N^s} \sum_{n=1}^{N^s} \log p(y_{n,m}^s | z_{n,m}^s)$$
其中 $H_{Y,m}^s$ 是与模型参数无关的常数。
2.3.3 信息瓶颈损失的具体形式
综合上述推导(忽略常数项),信息瓶颈损失为:
$$L_{IB}(\theta) = \sum_{m=1}^{M+1} \left[ \frac{\beta}{2} \log |\Sigma_m^s| - \frac{1}{N^s} \sum_{n \in [N^s]} \log p(y_{n,m}^s | z_{n,m}^s) \right]$$
其中:
- 第一项是表示的正则化项,抑制噪声和无效信息
- 第二项对应预测的负对数似然(等价于交叉熵损失)
关键设计:每个模态 $m$ 被强制独立生成自己的最优表示,这促进了模态独立性,防止弱模态被强模态主导。
2.4 伪标签投票策略
2.4.1 目标域伪标签生成
由于目标域数据无标注,Boomda 引入投票策略为样本生成伪标签:
给定所有模态的预测 $\hat{y}_{n,m}^t$(假设为 one-hot 向量),投票结果为:
$$\hat{y}n^t = \sum{m \in [M+1]} \hat{y}_{n,m}^t$$
其中 $(\hat{y}_n^t)_c$ 表示样本 $n$ 被分类为类别 $c$ 的票数。
2.4.2 可靠性筛选
为确保标签可靠性,仅选择获得至少 $M_v$ 票同类别投票的样本构成伪标签集:
$$\mathcal{N}_v^t = {n \mid \max{(\hat{y}_n^t)_1, \cdots, (\hat{y}_n^t)_C} \geq M_v, n \in [N^t]}$$
选中样本的伪标签为:
$$\bar{y}_n^t = \arg\max_c {(\hat{y}_n^t)_c \mid c = 1, 2, \cdots, C}, \quad \forall n \in \mathcal{N}_v^t$$
2.4.3 伪标签监督损失
伪标签作为目标域训练的监督信号,最小化以下交叉熵损失:
$$L_{PL}(\theta) = \frac{1}{|\mathcal{N}v^t|} \sum{n \in \mathcal{N}v^t} \sum{c \in [C]} -(\bar{y}n^t)_c \log (\hat{y}{n,M+1}^t)_c$$
设计优势:利用多模态的一致性投票,提高伪标签的可靠性;仅对高置信度样本进行监督,降低噪声影响。
2.5 相关对齐
2.5.1 逐模态表示对齐
Boomda 在每个模态自己的表示空间中分别对齐源域和目标域。具体地,首先计算 $Z_m^s$ 和 $Z_m^t$ 的相关矩阵 $C_m^s$ 和 $C_m^t$,然后通过最小化 Frobenius 范数来匹配表示:
$$L_{CA,m}(\theta) = |C_m^t - C_m^s|_F^2$$
这就是相关对齐(Correlation Alignment, Coral)损失。
2.5.2 对齐损失的收集
令 $\mathbf{L}{CA}(\theta) := [L{CA,1}(\theta), L_{CA,2}(\theta), \cdots, L_{CA,M+1}(\theta)]^T$ 收集所有模态的对齐损失。
2.6 多目标优化与MGDA
2.6.1 问题建模
直接聚合各模态对齐损失的朴素方法是加权求和,但这存在以下问题:
1. 缺乏先验知识时难以指定各模态权重
2. 模态数量大时搜索最优权重计算开销高
3. 预定义固定权重难以适应训练过程中对齐损失的动态变化
为解决上述问题,Boomda 将多模态对齐问题建模为多目标优化问题:
$$\min_\theta \mathbf{h}(\mathbf{L}{CA}(\theta)) := [L{CA,1}(\theta), L_{CA,2}(\theta), \cdots, L_{CA,M+1}(\theta)]^T$$
2.6.2 Pareto 最优性
定义 1(Pareto 最优性):
(a) 解 $\theta$ 支配另一个解 $\theta'$,如果 $\mathbf{L}{CA}(\theta) \neq \mathbf{L}{CA}(\theta')$ 且对所有 $m \in {1, 2, \cdots, M}$ 都有 $L_{CA,m}(\theta) \leq L_{CA,m}(\theta')$;
(b) 解 $\theta^$ 是 Pareto 最优的,如果不存在任何解支配 $\theta^$。
2.6.3 MGDA 算法
Boomda 采用多梯度下降算法(Multiple Gradient Descent Algorithm, MGDA)求解问题。MGDA 基于 Karush-Kuhn-Tucker (KKT) 条件,定义 Pareto 驻点:
任何解 $\theta$ 称为 Pareto 驻点,如果存在向量 $\gamma = [\gamma_1, \gamma_2, \cdots, \gamma_{M+1}]^T$ 满足:
- a) $\gamma \geq 0$
- b) $\mathbf{1}^T \cdot \gamma = 1$
- c) $\sum_{m \in [M+1]} \gamma_m \nabla_\theta L_{CA,m}(\theta) = 0$
求 Pareto 驻点涉及求解以下问题:
$$\text{P1:} \quad \min_\gamma \left| \sum_{m \in [M+1]} \gamma_m \nabla_\theta L_{CA,m}(\theta) \right|_2^2 \quad \text{s.t.} \quad \gamma \geq 0, \, \mathbf{1}^T \cdot \gamma = 1$$
设 $\gamma^$ 为 P1 的最优解,则有两种结果:
1. $\sum_{m} \gamma_m^ \nabla_\theta L_{CA,m}(\theta) = 0$,对应 $\theta$ 是 Pareto 驻点
2. $\sum_{m} \gamma_m^* \nabla_\theta L_{CA,m}(\theta) \neq 0$,这是所有目标的一个下降方向
2.6.4 计算优化
为提升计算效率,使用问题 P2 替代 P1:
$$\text{P2:} \quad \min_\gamma \left| \sum_{m \in [M+1]} \gamma_m \nabla_{Z_{M+1}} L_{CA,m}(\theta) \right|_2^2 \quad \text{s.t.} \quad \gamma \geq 0, \, \mathbf{1}^T \cdot \gamma = 1$$
P2 只需计算 $\nabla_{Z_{M+1}} L_{CA,m}(\theta)$ 而非 $\nabla_\theta L_{CA,m}(\theta)$,显著降低了计算开销,尤其适用于深度神经网络。
2.7 高效闭式解
2.7.1 模型结构的特殊性质
Boomda 进一步挖掘了模型结构的特殊性质。定义:
$$g_m := \nabla_{Z_m} L_{CA,m}(\theta), \quad g_{m,M+1} := \nabla_{Z_m} L_{CA,M+1}(\theta), \quad \forall m \in [M]$$
则梯度矩阵 $\mathbf{P}$ 具有如下特殊结构:
$$\mathbf{P} = \begin{bmatrix}
g_1 & 0 & \cdots & 0 \
0 & g_2 & \cdots & 0 \
\vdots & \vdots & \ddots & \vdots \
g_{1,M+1} & g_{2,M+1} & \cdots & g_{M,M+1}
\end{bmatrix}$$
2.7.2 二次规划问题
利用上述性质,问题 P2 可等价地写为:
$$\text{P3:} \quad \min_\gamma \gamma^T \mathbf{P} \mathbf{P}^T \gamma = \gamma^T \mathbf{Q} \gamma \quad \text{s.t.} \quad \gamma \geq 0, \, \mathbf{1}^T \cdot \gamma = 1$$
其中 $\mathbf{Q} := \mathbf{P} \mathbf{P}^T$。
2.7.3 对角近似与闭式解
实验观察到 $\mathbf{Q}$ 的非对角元绝对值远小于对角元,说明 $\mathbf{Q}$ 是正定矩阵。进一步用对角矩阵 $\tilde{\mathbf{Q}}$ 近似 $\mathbf{Q}$,得到问题 P4:
$$\text{P4:} \quad \min_\gamma \gamma^T \tilde{\mathbf{Q}} \gamma \quad \text{s.t.} \quad \gamma \geq 0, \, \mathbf{1}^T \cdot \gamma = 1$$
定理 1:问题 P4 具有闭式解:
$$\gamma = \frac{\tilde{\mathbf{Q}}^{-1} \mathbf{1}}{\mathbf{1}^T \tilde{\mathbf{Q}}^{-1} \mathbf{1}}$$
证明思路:利用拉格朗日乘子法,在无不等式约束条件下(因对角元均为正,解自然满足非负约束),直接求解可得上述闭式解。
意义:避免了迭代求解二次规划问题,每轮训练只需简单的矩阵运算即可获得最优权重,大幅提升训练效率。
2.8 整体算法流程
2.8.1 整体损失函数
获得系数 $\gamma$ 后,整体损失函数为:
$$L(\theta) = L_{IB}(\theta) + \alpha_1 L_{PL}(\theta) + \alpha_2 \sum_{m \in [M+1]} \gamma_m L_{CA,m}(\theta)$$
其中 $\alpha_1$ 和 $\alpha_2$ 是平衡各损失的常数系数。
2.8.2 算法伪代码
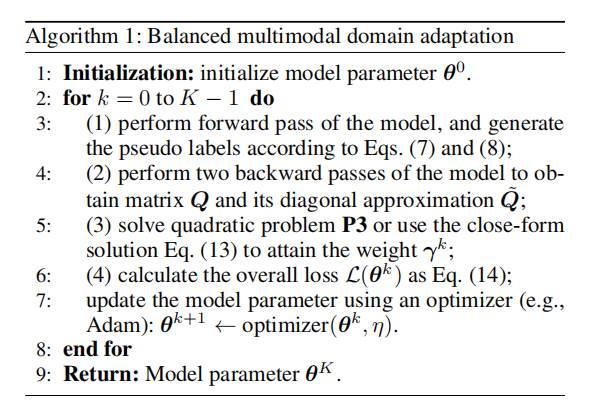
算法 1:平衡多模态域适应算法
算法流程总结如下:
- 初始化:模型参数 $\theta_0$
- 循环($k = 0$ 到 $K-1$):
- (1) 前向传播,根据公式 (7) 和 (8) 生成伪标签
- (2) 两次反向传播获得矩阵 $\mathbf{Q}$ 及其对角近似 $\tilde{\mathbf{Q}}$
- (3) 求解二次规划问题 P3 或使用闭式解 (13) 获得权重 $\gamma_k$
- (4) 计算整体损失 $L(\theta_k)$
- 使用优化器(如 Adam)更新模型参数
- 返回:模型参数 $\theta_K$
2.8.3 超参数设置
根据论文实验:
- $\beta$(信息瓶颈系数):$5 \times 10^{-4}$
- $\alpha_1$(伪标签损失权重):$0.5$
- $\alpha_2$(对齐损失权重):$0.1$
- $M_v$(投票阈值):$3$
- 表示维度 $d$:$256$
- 学习率:$1 \times 10^{-3}$
- 批次大小:$48$
本节小结
- Boomda 的模型包含预训练骨干、序列编码器和分类器三层结构
- 信息瓶颈损失确保各模态独立学习最优表示,促进模态独立性
- 伪标签投票策略利用多模态一致性为目标域生成可靠监督信号
- 相关对齐在各模态表示空间中匹配源域和目标域的协方差结构
- 多目标优化将各模态对齐建模为竞争目标,通过 MGDA 求解 Pareto 最优
- 闭式解避免了迭代优化,实现高效的模态平衡训练
公式速查表
| 公式 | 名称 | 用途 |
|---|---|---|
| $L_{IB}(\theta) = \sum_{m} \beta I(X_m^s, Z_m^s) - I(Z_m^s, Y_m^s)$ | 信息瓶颈损失 | 学习各模态最优表示 |
| $L_{PL}(\theta)$ | 伪标签损失 | 目标域监督 |
| $L_{CA,m}(\theta) = |C_m^t - C_m^s|_F^2$ | 相关对齐损失 | 域对齐 |
| $\gamma = \tilde{\mathbf{Q}}^{-1}\mathbf{1} / (\mathbf{1}^T \tilde{\mathbf{Q}}^{-1}\mathbf{1})$ | 闭式解 | 模态平衡权重 |
思考题
- 信息瓶颈损失中的 $\beta$ 系数如何影响表示学习?$\beta$ 过大或过小分别会导致什么问题?
- 伪标签投票策略中阈值 $M_v$ 的选择如何影响训练?
- 为什么说问题 P4 的闭式解避免了迭代优化?计算复杂度有何优势?
- 如果某个模态在所有迭代中的对齐损失都远小于其他模态,MGDA 会赋予它什么样的权重?这是否合理?