第四章:实验与结果分析
4.1 数据集介绍
4.1.1 IEMOCAP 数据集
基本信息:
- 全称:Interactive Emotional Dyadic Motion Capture Database
- 模态:声学(Acoustic)、视觉(Visual)、词汇(Lexical)
- 内容:演员之间的脚本化和自发性二元对话
- 类别:4 类情感 — neutral、happy、sad、angry
- 划分: evenly 且随机划分为两个子集,一个作为源域,另一个经处理后作为目标域
目标域处理(模拟域偏移):
- 声学模态:注入白噪声,信噪比 SNR = 1.0
- 视觉模态:视频亮度降至原始的 20%,并添加高斯噪声(SNR = 0.5)
- 词汇模态:每个话语中 40% 的单词被随机掩码
4.1.2 MSP-IMPROV 数据集
基本信息:
- 全称:MSP-IMPROV Corpus
- 模态:声学、视觉、词汇
- 内容:参与者的广泛自发性互动,无脚本对话
- 类别:与 IEMOCAP 相同的 4 类情感
- 划分方式:同 IEMOCAP
4.1.3 数据集对比
| 数据集 | 对话类型 | 模态数 | 域偏移方式 | 主要挑战 |
|---|---|---|---|---|
| IEMOCAP | 脚本+自发 | 3 | 噪声、亮度降低、掩码 | 偏移程度大 |
| MSP-IMPROV | 完全自发 | 3 | 同上 | 情感表达更自然 |
4.2 实现细节
4.2.1 骨干网络配置
| 模态 | 预训练模型 | 后续编码器 | 微调策略 |
|---|---|---|---|
| 声学 (A) | WavLM | TextCNN | 最后三层可训练 |
| 视觉 (V) | APViT (RAF-DB 预训练) | 单层 LSTM | 最后三层可训练 |
| 词汇 (L) | Bert-base | TextCNN | 最后三层可训练 |
4.2.2 训练配置
- 表示维度 $d$:256
- 优化器:Adam($\beta_1=0.9, \beta_2=0.999$)
- 学习率:$1 \times 10^{-3}$
- 批次大小:48
- 超参数:
- $\beta = 5 \times 10^{-4}$
- $\alpha_1 = 0.5$
- $\alpha_2 = 0.1$
- $M_v = 3$
- 评估指标:Weighted F1 score
- 运行环境:4 块 Nvidia A40 GPU(48 GB 显存),取 3 次运行平均
4.3 与SOTA方法的对比
4.3.1 实验设置
对比方法包括:
- D.T.(Direct Transfer):仅用源域数据训练,直接测试目标域
- DANN:域对抗神经网络
- CDAN:条件对抗域适应
- MADA:多对抗域适应
- DALN:无判别器对抗域适应
- PCL:概率对比学习域适应
- DADA:基于数据增强的域适应
实验模态组合:AL(声学+词汇)、AV(声学+视觉)、VL(视觉+词汇)、AVL(三模态)
4.3.2 IEMOCAP 结果(表 1)
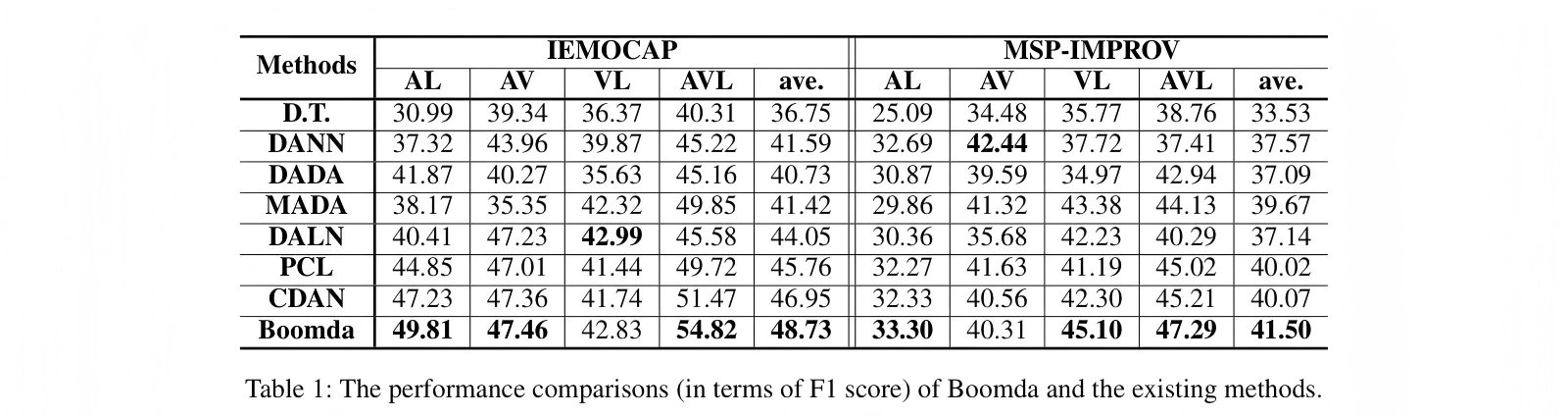
表 1:Boomda 与现有方法的性能对比(Weighted F1 score)
| 方法 | AL | AV | VL | AVL | ave. |
|---|---|---|---|---|---|
| D.T. | 30.99 | 39.34 | 36.37 | 40.31 | 36.75 |
| DANN | 37.32 | 43.96 | 39.87 | 45.22 | 41.59 |
| DADA | 41.87 | 40.27 | 35.63 | 45.16 | 40.73 |
| MADA | 38.17 | 35.35 | 42.32 | 49.85 | 41.42 |
| DALN | 40.41 | 47.23 | 42.99 | 45.58 | 44.05 |
| PCL | 44.85 | 47.01 | 41.44 | 49.72 | 45.76 |
| CDAN | 47.23 | 47.36 | 41.74 | 51.47 | 46.95 |
| Boomda | 49.81 | 47.46 | 42.83 | 54.82 | 48.73 |
关键发现:
-
全面领先:在 IEMOCAP 数据集上,Boomda 在 4 个模态组合中的 3 个(AL、VL、AVL)取得最佳性能,平均 F1 超过所有对比方法至少 1.78。
-
融合性能显著提升:AVL 设置下达到 54.82,比次优方法 CDAN(51.47)高出 3.35 分,充分验证了模态平衡的价值。
-
模态增加不退化:部分方法在增加模态时性能下降(如 DALN 的 AV 47.23 -> AVL 45.58),而 Boomda 随模态增加持续提升。
4.3.3 MSP-IMPROV 结果(表 1 右侧)
| 方法 | AL | AV | VL | AVL | ave. |
|---|---|---|---|---|---|
| D.T. | 25.09 | 34.48 | 35.77 | 38.76 | 33.53 |
| DANN | 32.69 | 42.44 | 37.72 | 37.41 | 37.57 |
| ... | ... | ... | ... | ... | ... |
| Boomda | 33.30 | 40.31 | 45.10 | 47.29 | 41.50 |
关键发现:
- Boomda 平均 F1 超过所有对比方法至少 1.43
- 在 AV 设置上略低于 CDAN,但在 VL 和 AVL 上优势明显
- 再次验证了模态平衡在多模态融合中的重要性
4.4 消融实验
4.4.1 实验设计
在 IEMOCAP 数据集上进行消融实验,分析两个核心设计的贡献:
- 平衡相关对齐(CA):多目标优化平衡的对齐
- 伪标签(PL):目标域伪标签监督
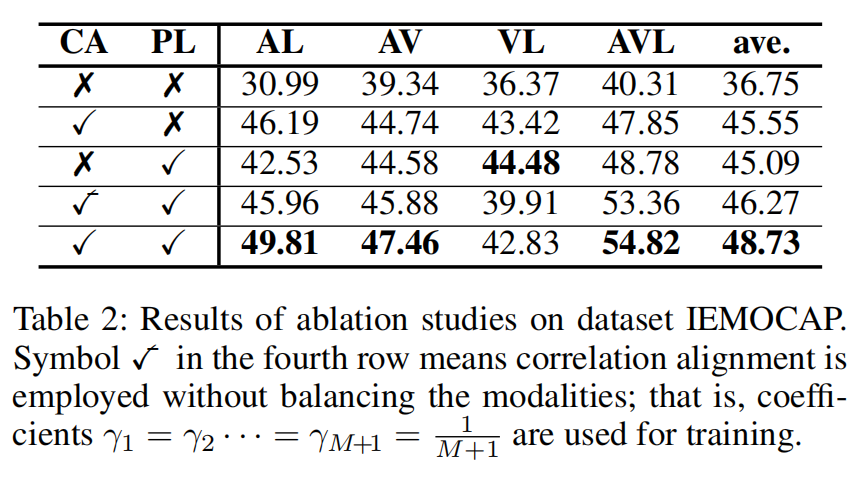
表 2:IEMOCAP 数据集上的消融实验结果
| CA | PL | AL | AV | VL | AVL | ave. |
|---|---|---|---|---|---|---|
| ✗ | ✗ | 30.99 | 39.34 | 36.37 | 40.31 | 36.75 |
| ✓ | ✗ | 46.19 | 44.74 | 43.42 | 47.85 | 45.55 |
| ✗ | ✓ | 42.53 | 44.58 | 44.48 | 48.78 | 45.09 |
| ✓̄ | ✓ | 45.96 | 45.88 | 39.91 | 53.36 | 46.27 |
| ✓ | ✓ | 49.81 | 47.46 | 42.83 | 54.82 | 48.73 |
注:✓̄ 表示使用相关对齐但不做模态平衡(即 $\gamma_1 = \gamma_2 = \cdots = \gamma_{M+1} = \frac{1}{M+1}$)
4.4.2 结果分析
(1)各组件独立贡献
- 仅加入 CA(平衡相关对齐):平均 F1 从 36.75 提升到 45.55(+8.80)
- 仅加入 PL(伪标签):平均 F1 从 36.75 提升到 45.09(+8.34)
两者各自都能带来超过 8 分的显著提升,说明两个组件都是有效的。
(2)联合使用效果
当两个技术联合使用时,平均 F1 进一步提升到 48.73,相比单独使用任一组件提升约 3 分,证明了两者的互补性。
(3)模态平衡的价值
对比最后两行:
- 不加权平衡(✓̄):平均 46.27
- 加权平衡(✓):平均 48.73
模态平衡带来了约 2.5 分的性能提升,验证了多目标优化框架的有效性。
(4)特定模态组合分析
- 在 AL 设置上,平衡对齐的提升尤为显著(45.96 -> 49.81)
- 在 VL 设置上,不加权平衡反而导致性能下降(44.48 -> 39.91),说明固定平均权重在某些模态组合上是有害的
4.5 训练动态可视化
4.5.1 矩阵 Q 的特征
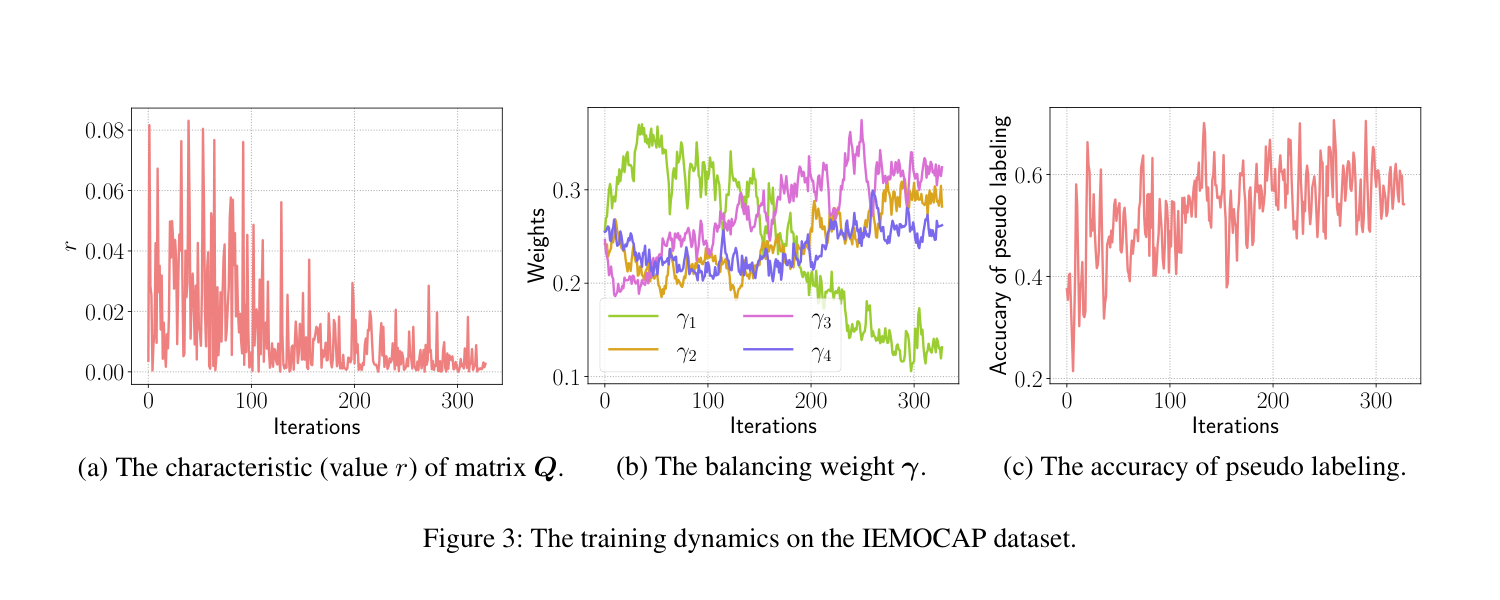
图 3:IEMOCAP 数据集上的训练动态
图 3(a) 展示了矩阵 $\mathbf{Q}$ 的特征值比值:
$$r := \frac{\max{|Q_{ij}| \mid i,j \in [M+1], i \neq j}}{\min{Q_{ii} \mid i \in [M+1]}}$$
关键发现:$r$ 在整个训练过程中保持较小值,这验证了用对角矩阵 $\tilde{\mathbf{Q}}$ 近似 $\mathbf{Q}$ 的合理性,为闭式解的有效性提供了实验支持。
4.5.2 平衡权重 $\gamma$ 的演化
图 3(b) 展示了训练过程中各模态平衡权重 $\gamma$ 的变化:
- 早期阶段:声学模态($\gamma_1$)被赋予相对较大的权重
- 后期阶段:声学模态的权重逐渐降低,视觉和词汇模态的权重相应调整
直观解释:在训练初期,声学模态可能需要更强的对齐信号来适应目标域的噪声;随着训练进行,各模态逐渐达到平衡状态。
4.5.3 伪标签准确率
图 3(c) 展示了每轮训练中伪标签的准确率:
- 伪标签准确率随训练过程呈现上升趋势
- 这说明随着模型性能提升,投票生成的伪标签越来越可靠
- 可靠的伪标签反过来又促进了目标域的学习,形成良性循环
本节小结
- IEMOCAP 和 MSP-IMPROV 是两个广泛使用的多模态情感识别基准数据集
- Boomda 在两个数据集的所有模态组合上均一致超越现有 SOTA 方法
- 消融实验验证了平衡相关对齐和伪标签两个组件的独立贡献和协同效应
- 模态平衡(动态权重)相比固定平均权重带来约 2.5 分的性能提升
- 训练动态分析证明了闭式解近似的合理性以及伪标签质量的持续提升
思考题
- 为什么在 VL 设置上,不加权平衡(固定平均权重)会导致性能下降?这与模态特性有何关系?
- 伪标签准确率从初期到末期的提升幅度大约是多少?这对训练稳定性有何启示?
- 如果训练过程中 $r$ 值突然增大,可能意味着什么?应该如何调整方法?
- Boomda 在 MSP-IMPROV 上的平均提升(1.43)小于 IEMOCAP(1.78),可能的原因是什么?